
NLP-> Architecting Zero-Intervention Data Pipelines: The "Playing XI" Blueprint
How to decouple LLMs from Delta Lake, cut compute costs by ~30%, and drive hallucinations below 1%.

Modern Lakehouse environments suffer from "The Dashboard Paradox": data is abundant, but insights are delayed by manual SQL engineering and pipeline fragility. Standard "Black Box" LLM wrappers fail at scale because they hallucinate SQL and run expensive, broken queries on large datasets.
From NLP to On-Demand Insights
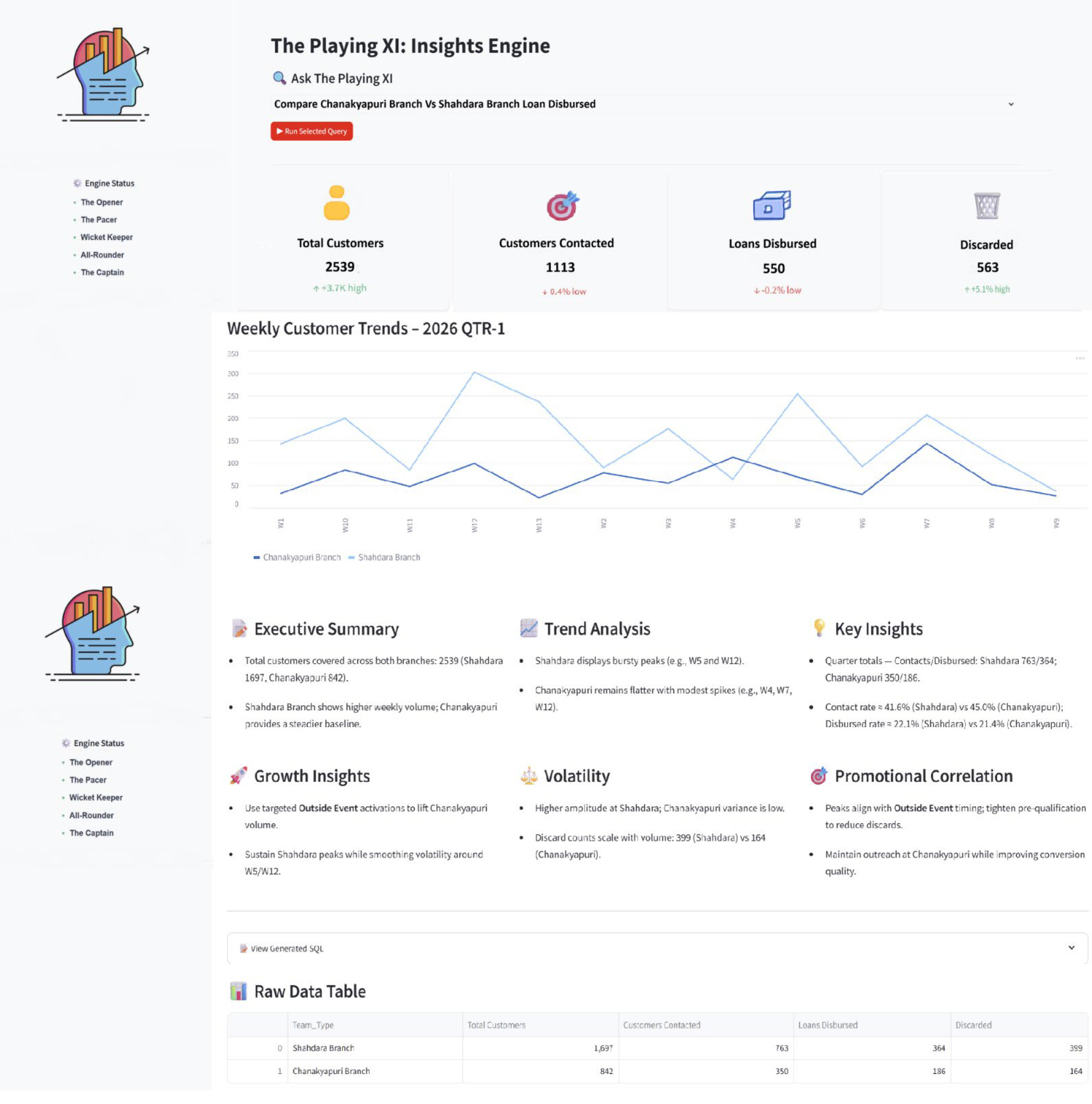
What you are looking at is a dynamic Streamlit UI powered entirely by our decoupled multi-agent architecture. We fed the system a simple, conversational natural language query alongside raw business data, and it autonomously engineered the entire layout on the fly.
Within seconds, the multi-agent engine:
Generates optimized, error-free Spark SQL to pull from Delta Lake.
Synthesizes a structured narrative Executive Summary.
Automatically charts key metrics, trend analysis, and volatility spikes.
No manual dashboard building, no hardcoded charts—just deterministic data orchestration turning a single line of human intent into production-grade analytics.
To solve this, I designed The Playing XI—a Decoupled Multi-Agent Orchestration Layer that bridges natural language intent to Delta Lake execution with Zero Hallucination.
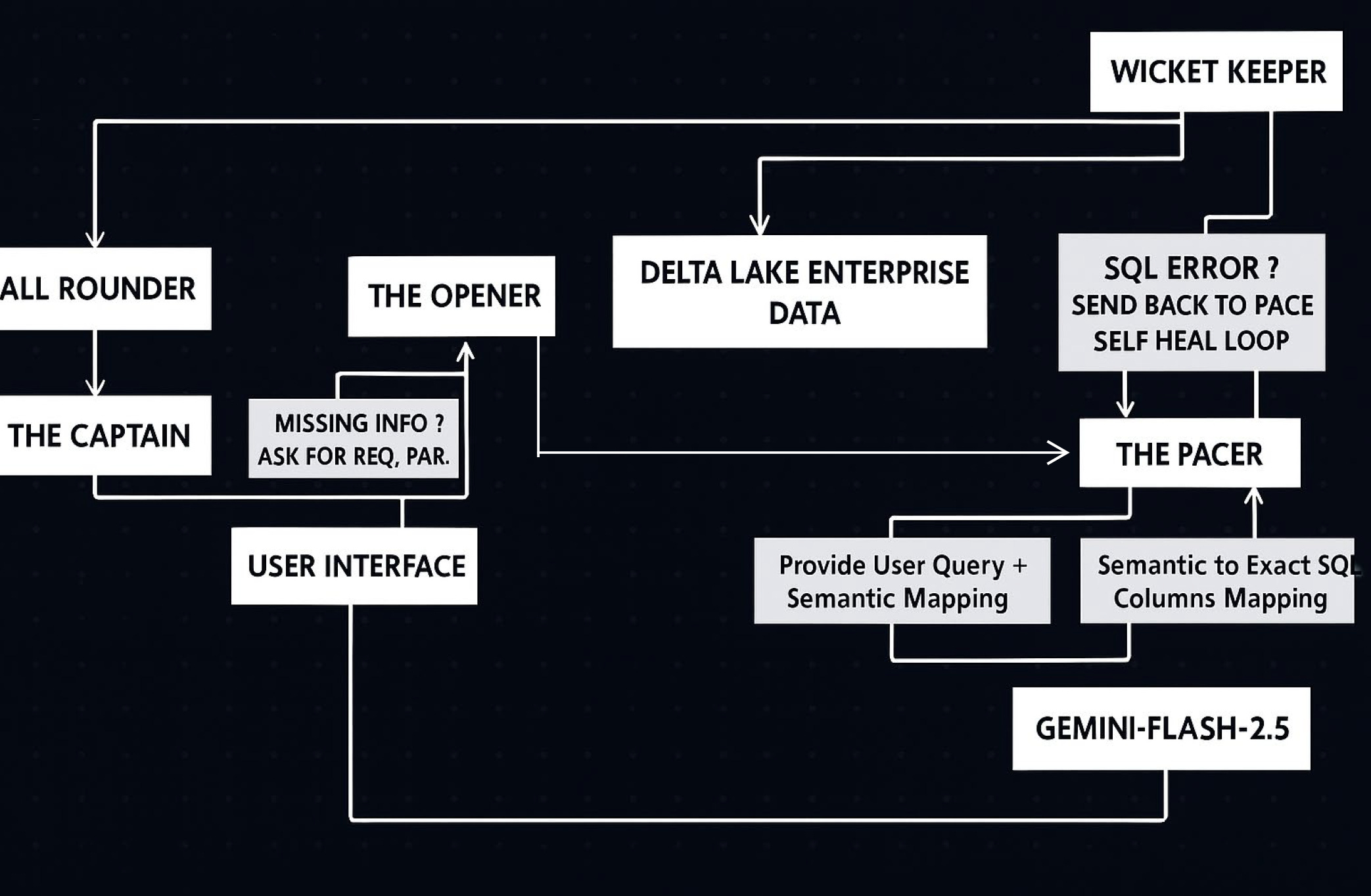
The Golden Rule: 0 Direct Interaction The core of this architecture is simple: The execution layer (Databricks) processes the data, ensuring the LLM NEVER touches the raw Delta Lake tables. This single constraint drops hallucinations to near zero.
The Tech Stack
Orchestration: LangGraph (Stateful Agent Management).
Intelligence: Gemini 2.5 Flash (Google AI Studio).
Data Backbone: Databricks Medallion Architecture (Delta Lake).
Compute Execution: Decoupled Remote Execution via DBX CLI.
The “Playing XI” Multi-Agent Logic. Instead of one massive prompt, the intelligence is partitioned into specialized micro-agents:
The Opener: Maps NLP to verified metadata (Intent & Schema Grounding).
The Pacer: Translates intent to optimized Spark SQL (Deterministic SQL Generation).
Wicket Keeper: Performs dry-runs and P&L audit (Autonomous Observability).
All-Rounder: Merges data with business metadata (Contextual Synthesis).
The Captain: Ensures final output matches initial intent (Stateful Gateway).
Autonomous Self-Healing: The Wicket Keeper Loop. We achieve 0% human intervention and ~30% compute cost reduction through the Wicket Keeper agent. It injects a WHERE 1=0 condition to safely test the generated query against the Databricks cluster without incurring compute waste. If schema drift or syntax errors occur, the state machine automatically catches the exception and routes the error feedback back to The Pacer. The Pacer natively rewrites and fixes the Spark SQL based on the error log without requiring any manual developer debugging.
If you are dealing with massive data orchestration and want to build enterprise-grade Agentic AI, subscribe to follow this journey. Stay Connected!